Using DKube¶
This section provides an overview of DKube, and allows you to get started immediately.
DKube Roles, Workflow, & Cluster Types¶

DKube operation is based on MLOps roles and workflow. The workflow for each role will run on a specific type of cluster.
Workflow |
Role |
Description |
Cluster Type |
|---|---|---|---|
Prototyping |
Data Scientist |
Code development |
Training |
Productization |
ML Engineer |
Optimize model for deployment |
Training |
Production Serving |
Production Engineer |
Deploy and monitor models for live inference |
Serving |
The workflow is described in more detail in the section MLOps Concepts. The following section summarizes the expected workflow:
The Data Scientist (DS) and ML Engineer (ML Eng) create and optimize models based on specific goals and metrics
The Production Engineer takes the models produced by the ML Eng and deploys them for inference serving after validating them
The following section describes the nomenclature and workflow for the activities that happen on the Training cluster. This includes creating and optimizing models for possible deployment.
The description of the activities that happen on the Serving cluster, including deploying models for live inference, are described at Production Engineer Dashboard & Workflow.
DKube Training Activities¶
This section provides the information that you need to start to using DKube quickly. Your access to DKube will depend upon your role. There are 2 different roles associated with DKube.
Role |
Responsibilities |
|---|---|
Operator |
|
Data Scientist |
|
If the User is logged in as an Operator, the dashboards can be selected at the top right-hand side of the screen (circled in the screen shot). Once selected, the dashboards toggle between the Operator & Data Scientist views. The details of the dashboards are provided in the following sections.

First Time Users¶
If you want to jump directly to a guided example, go to the Data Scientist Tutorial. This steps you through the Data Scientist workflow using a simple example.
If you want to start with your own program and dataset, follow these steps.
Load the Projects and Datasets into DKube (Section Projects)
Create a Notebook (Section Create IDE)
Create a Training Run (Section Runs)
Test or deploy the trained Model (Section Models )
Otherwise, the following sections provide the concepts for the Operator and Data Scientist roles.
Operator Role¶
If you are an Operator, you will have access to both the Operator and Data Science roles. By default, DKube enables operation without needing to do setup from the Operator. The Operator User is on-boarded and authenticated during the installation process, and this User is also enabled as a Data Scientist.
The Operator role also performs the ML Eng tasks within the DKube MLOps workflow ( MLOps Concepts ).
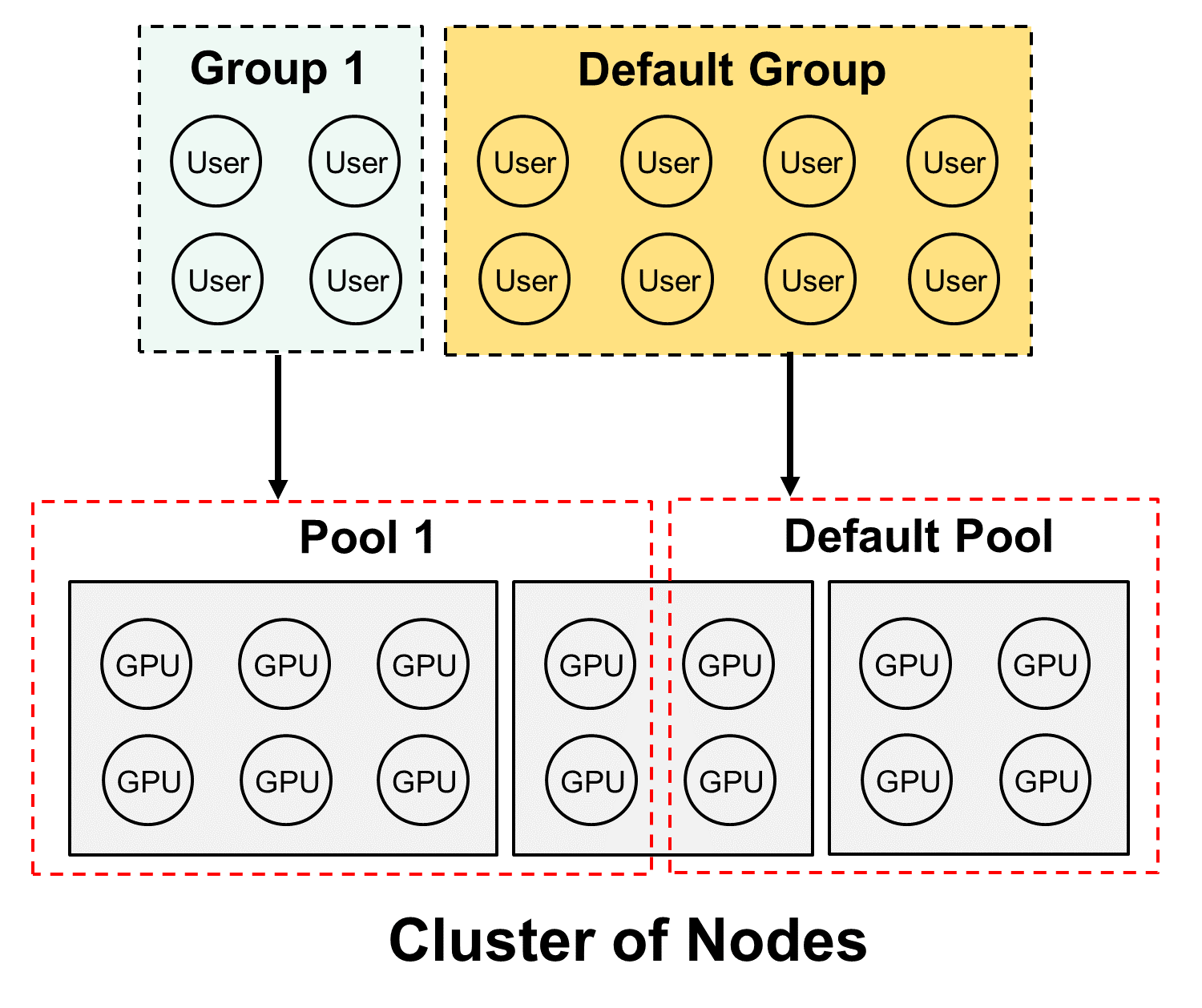
DKube Operator Concepts¶
Concept |
Definition |
|---|---|
User |
Operator or Data Scientist |
Group |
Aggregation of Users
|
GPU |
GPU devices connected to the Node
|
Node |
Execution entity
|
Pool |
Aggregation of GPUs
|
Operation of Pools¶
Pools are collections of GPUs assigned to Groups. The GPUs in the Pool are shared by the Users in the Group.
A Pool can only contain one type of GPU; this includes any resources for that GPU, such as memory
The Users in a Group share the GPUs in the Pool
As GPUs are used by Runs or other entities, they reduce the number of GPUs available to other Users in the Group. Once the Run is complete (or stopped), the GPUs are made available for other Runs.
Default Pool and Group¶
DKube includes a Group and Pool with special properties, called the Default Group and Default Pool. They are both available when DKube is installed, and cannot be deleted. The Default Group and Pool allow Users to start their work as Data Scientists without needing to do a lot of setup.
The Default Pool contains all of the GPUs that have not been allocated to another Pool by the Operator. As the GPUs are discovered and automatically on-boarded, they are placed in the Default Pool.
As additional Pools are created, and GPUs are allocated to the new Pools, the number of GPUs in the Default Pool are reduced
As GPUs are removed from the other (non-Default) Pools, those GPUs are allocated back into the Default Pool
The total number of GPUs in all of the Pools will always equal the total number of GPUs across the cluster, since the Default Pool will always contain any GPU not allocated to any other Pool
The Default Group automatically gets the allocation of the Default Pool, and it contains all of the on-boarded Users who are allocated to the Default Group.
As new Users are on-boarded, they are assigned to the Default Group unless a different assignment is made during the on-boarding process
Users can be moved from the Default Group to another Group using the same steps as from any other Group
Clustered Pools¶
Pools behave differently depending upon whether the GPUs are spread across the cluster, or on a single node. If all of the GPUs in a Pool are on a single node, no special treatment is required to operate as described above.
If the GPUs in a pool are distributed across more than a single node, the Advanced option must be selected when submitting a Run. This process is described in the section Create Training Run.
Initial Operator Workflow¶
At installation time, default Pools & Groups have been created, and the Operator is added to the Default Pool.
The Default Pool contains all of the resources
The Operator has been added to the Default Group
The Data Scientist can start without needing to do any resource configuration
If Pools and Groups are required in addition to the Default, the following steps can be followed:
Create Additional Pools (Section Create Pool)
Assign Devices to the Pools
Create Additional Groups (Section Create Group)
Assign a Pool to each new Group
Add (On-Board) Users (Section Add (On-Board) User)
Assign Users to one of the new Groups
New Users can still be assigned to the Default Group if desired
If the Operator is the only User, or if all of the Users - including other Data Scientists - are in the same Group, nothing else needs to be done from the Operator workflow to get started.
The Operator should select the Data Scientist dashboard
The following section describes how to get started as a Data Scientist
Data Scientist Role¶
If you are a Data Scientist, you will only have access to the Data Scientist role, menus, and screens.
Several example programs with their associated datasets and test data have been provided on GitHub. The locations are described in section Example Project and Dataset Locations
The programs and datasets can be downloaded through the Projects and Datasets screens, and data science can begin.
A tutorial that takes you through your first usage is available at Data Scientist Tutorial
DKube Data Scientist Concepts¶


DKube Concepts¶
Concept |
Definition |
|---|---|
Projects |
Directory containing program code for IDEs and Runs |
Datasets |
Directory containing training data for IDEs and Runs |
IDEs |
Experiment with different Projects, datasets, and hyperparameters |
Runs |
Formal execution of code
|
Models |
Trained models, ready for deployment or transfer learning |
Pipeline Concepts¶
Concept |
Definition |
|---|---|
Pipeline |
Kubeflow Pipelines - Portable, visual approach to automated deep learning |
Experiments |
Aggregation of runs |
Runs |
Single cycle through a pipeline |
Note
The concepts of Pipelines are explained in section Kubeflow Pipelines
Shared Data¶
Users in a Group share projects, datasets, notebooks, runs, & models. These are shown on the screens for each type of data. At the top left-hand of the screen there is a dropdown menu that allows the User to select what is visible: just the User’s data, just the shared data, or both.

Tags & Description¶
Most instances can have Tags associated with them, provided by the user when the instance is downloaded or created. Some instances, such as Runs, also have a Description field.
Tags and Descriptions provide an alphanumeric field that become part of the instance. They have no impact on the instance within DKube, but can be used to group entities together, or by a post-processing filter created by the Data Scientist to store information about the instance such as release version, framework, etc.
The Tag field can have as many as 256 characters.
Run Scheduling¶
When a Run is submitted (see Runs ), DKube will determine whether there are enough available GPUs in the Pool associated with the shared Group. If there are enough GPUs, the Run will be scheduled immediately.
If there are not currently enough GPUs available in the Pool, the Run will be queued waiting for enough GPUs to become available. As the currently executing Runs are completed, their GPUs are released back into the Pool, and as soon as there are sufficient GPUs the queued Run will start.
It is possible to instruct the scheduler to initiate a Run immediately, without regard to how many GPUs are available. This directive is provided by the user in the GPUs section when submitting the Run.
Status Field of IDEs & Runs¶
The status field provides an indication of how the IDE or Run is progressing. The meaning of each status is provided here.
Status |
Description |
Applies To |
|---|---|---|
Queued |
Initial state |
All |
Waiting for GPUs |
Released from queue; waiting for GPUs |
All |
Starting |
Resources available; Run is starting |
All |
Running |
Run is active |
All |
Training |
Training Run is running |
Training Run |
Complete |
Run is complete; resources released |
All |
Error |
Run failure |
All |
Stopping |
Run in process of stopping |
All |
Stopped |
Run stopped; resources released |
All |
MLOps Concepts¶

DKube supports a full MLOps workflow. Although the application is very flexible and can accommodate different workflows, the expected MLOps workflow is:
Code development and experimentation are performed by a Data Scientist. Many Models will be generated as the Data Scientist progresses. The Model that is best suited to solving the problem is then Released to the ML Engineer.
The release process provides the full context of the Model as described in Tracking and Lineage. This allows reproducibility, and lets the ML Eng start with the existing Model and create more runs with different datasets, hyperparameters, and environments.
The ML Engineer takes that Model and prepares it for production. The ML Engineer will also be generating many Models during the optimization and productization phase of development. The resulting optimized Model is then Published to identify that it is ready for the Production Engineer to review and deploy.
Within DKube, the Operator Role ( Operator Role ) fulfils the role of the ML Eng, using the Data Scientist screens and workflow to optimize and publish models.
The Published Model is added to the Model Catalog. The Model Catalog contains all of the Models that have been completed by the ML Eng, and are candidates for deployment.
The Production Engineer (described in section Production Engineer Dashboard & Workflow) does testing on the published model that is in the Model Catalog, and when satisfied that it is better than the current version, Deploys the Model for live inference.
The details of this workflow are provided in the section Models.
Comparing Models¶
As part of the standard model delivery workflow, Data Scientists and ML Engineers need to be able to compare several models to understand how the key metrics trend. This is described in the section Compare Models.
Tracking and Lineage¶

When working with large numbers of complex models, it is important to be able to understand how different inputs lead to corresponding outputs. This is always valuable, since the user might want to go back to a previous Run and either reproduce it or make modifications from that base. And in certain markets it is mandatory for regulatory or governance reasons.
Run, Model, and Dataset Lineage¶
DKube tracks the entire path for every Run and Model, and for each Dataset that is created from a Preprocessing Run. It is saved for later viewing or usage. This is called Lineage. Lineage is available from the detailed screens for Runs, Models, and Datasets. Run lineage is described in the section Lineage.
Dataset Usage¶
DKube keeps track of where each version of each Dataset is used, and shows them in the detailed screens for the Dataset version. This can be used to determine if the right distribution of Datasets is being implemented.
Versioning¶

Datasets and Models are provided version control within DKube. The versioning is accomplished by integrating DVC into the DKube system. The version control is part of the workflow and UI.
In order to set up the version control system within DKube, the versioned repository must first be created. This is explained in section DVS.
The metadata information (including the version information) and the data storage repo are set up. The location for the data is specified, and the repo is given a name. This will create version 1 of the entity (Dataset or Model).
The DVS repo name is used when creating a Dataset or Model, as explained in section Repos.
When a Run in executed:
A new version of a Model is created by a Training Run
A new version of a Dataset is created by a Preprocessing Run
The version system will automatically create a new version of the Model or Dataset, incrementing the version number after each successful Run.
The available versions of the Model or Dataset are available by selecting the detailed screen for that entity. The lineage and usage screens will identify what version of the Model or Dataset are part of the Run.
Hyperparameter Optimization¶
DKube implements Katib-based hyperparameter optimization. This enables automated tuning of hyperparameters for a Run, based upon target objectives.
This is described in more detail at Katib Introduction.
Katib Within DKube¶
The section Hyperparameter Optimization provides the details on how to use this feature within DKube.
Kubeflow Pipelines¶
Support for Kubeflow Pipelines has been integrated into DKube. Pipelines facilitate portable, automated, structured machine learning workflows based on Docker containers.
The Kubeflow Pipelines platform consists of:
A user interface (UI) for managing and tracking experiments and runs
An engine for scheduling multi-step machine learning workflows
An SDK for defining and manipulating pipelines and components
Notebooks for interacting with the system using the SDK
An overall description of Kubeflow Pipelines is provided below. The reference documentation is available at Pipelines Reference.
Pipeline Definition¶
A pipeline is a description of a machine learning workflow, including all of the components in the workflow and how they combine in the form of a graph. The pipeline includes the definition of the inputs (parameters) required to run the pipeline and the inputs and outputs of each component.
After developing your pipeline, you can upload and share it through the Kubeflow Pipelines UI.
The following provides a summary of the Pipelines terminology.
Term |
Definition |
|---|---|
Pipeline |
Graphical description of the workflow |
Component |
Self-contained set of code that performs one step in the workflow |
Graph |
Pictorial representation of the run-time execution |
Experiment |
Aggregation of Runs, used to try different configurations of your pipeline |
Run |
Single execution of a pipeline |
Recurring Run |
Repeatable run of a pipeline |
Run Trigger |
Flag that tells the system when a recurring run spawns a new run |
Step |
Execution of a single component in the pipeline |
Output Artifact |
Output emitted by a pipeline component |
Pipeline Component¶
A pipeline component is a self-contained set of user code, packaged as a Docker image, that performs one step in the pipeline. For example, a component can be responsible for data preprocessing, data transformation, model training, etc.
The component contains:
Term |
Definition |
|---|---|
Client Code |
The code that talks to endpoints to submit Runs |
Runtime Code |
The code that does the actual Run and usually runs in the cluster |
A component specification is in YAML format, and describes the component for the Kubeflow Pipelines system. A component definition has the following parts:
Term |
Definition |
|---|---|
Metadata |
Name, description, etc. |
Interface |
Input/output specifications (type, default values, etc) |
Implementation |
A specification of how to run the component given a set of argument values for the component’s inputs. The implementation section also describes how to get the output values from the component once the component has finished running. |
The Component specification is available at Kubeflow Component Spec.
You must package your component as a Docker image. Components represent a specific program or entry point inside a container.
Each component in a pipeline executes independently. The components do not run in the same process and cannot directly share in-memory data. You must serialize (to strings or files) all the data pieces that you pass between the components so that the data can travel over the distributed network. You must then deserialize the data for use in the downstream component.
Pipeline Example¶
The following screenshot shows an example of a pipeline graph, taken from one of the programs that is included as part of DKube.

The python source code that corresponds to the graph is shown here.

In order to create an experiment, a Run must be initiated.

After the Run is complete, the details of the run and the outputs can be viewed. Information about the Run, including the full graph and the details of the Run, are available by selecting the Run name. The Pipeline stage provides more information from the Run details screen .

Kubeflow Within DKube¶
The section Kubeflow Pipelines provides the details on how this capability is implemented in DKube.